程序结构
命名
命名规则:
- 以字母或下划线开头,接任意字母、数字或下划线(区分大小写)。保留关键字及预定义名不可用
- 名字首字母大小写决定该名在包外可见性
保留关键字
1
2
3
4
5break default func interface select
case defer go map struct
chan else goto package switch
const fallthrough if range type
continue for import return var预定义名
1
2
3
4
5
6
7
8
9
10内建常量: true false iota nil
内建类型: int int8 int16 int32 int64
uint uint8 uint16 uint32 uint64 uintptr
float32 float64 complex128 complex64
bool byte rune string error
内建函数: make len cap new append copy close delete
complex real imag
panic recover命名规范
使用驼峰式方式
包(package)名用小写,使用短命名
接口(interface)名,单方法接口以函数名+
er后缀,两个方法接口综合两个函数名+er后缀,三个以上取能精准描述接口目的的名字1
2
3
4
5
6
7
8type Reader interface {
Read(p []byte) (n int, err error)
}
type WriteFlusher interface {
Write([]byte) (int, error)
Flush() error
}局部变量/函数参数,使用小写字母,尽量短小
方法接收者(receiver)应该缩写,一般使用一个或者两个字符作为receiver的名称
包(package)级别导出名不要把包名的意义再写一遍,
bytes.Buffer,bytes.ByteBuffer
声明
声明语句,包(package)级声明语句顺序无关紧要
var: 变量const: 常量type: 类型func: 函数
声明示例
1 | var a int |
变量
变量声明
1 | var name type = expression // var age int = 18 |
type 和 = expression可二选一,省略type会根据expression推导变量类型(var name = expression),省略expression会用零值初始化变量(var name type),各类型零值:
- number:
0 - bool:
false - string:
“”(空字符串) - slice/pointer/map/chan/func/interface:
nil - array/struct: 每个元素/字段对于类型的零值
简短变量声明
函数内部可用简短变量声明语句声明和初始化局部变量(只能用于函数内部),变量类型根据表达式自动推导
1 | name := expression // age := 18 |
相同词法域中,简短变量声明过的变量只能赋值
1 | in, err := os.Open(infile) |
简短变量声明语句中必须至少要声明一个新变量,否则编译不通过
1 | f, err := os.Open(infile) |
简短变量声明只对同级词法域声明过的变量进行赋值操作,变量在外部词法域则是重新声明一个新的变量
1 | func main() { |
指针
一个指针类型变量的值是另一个变量的地址(指针存储变量在内存中的位置),通过指针可直接读或更新对应变量的值,不需要知道变量名
1 | x := 1 |
任何类型的指针的零值都是nil
p指向某个有效变量,那么p != nil测试为true
指针可进行相等测试,只有当它们指向同一个变量或全部是nil时才相等
new函数
new(T)
- 创建一个T类型匿名变量
- 初始化匿名变量为T类型零值
- 返回匿名变量地址,返回的指针类型为
*T
new(T)得到的是一个*T类型,值为T类型零值的匿名变量
1 | p := new(int) // p 类型为*int,值为0 |
赋值
1 | x = 1 // 命名变量的赋值 |
元组赋值,允许同时更新多个变量的值
当函数调用出现在元组赋值右边的表达式中时,左边变量的数目必须和右边一致
1 | x, y = y, x // 交换两个变量 |
如果map查找、类型断言或channel接收出现在赋值语句的右边,它们都可能会产生两个结果,有一个额外的布尔结果表示操作是否成功
1 | v, ok = m[key] // map查找 |
隐式赋值行为:
- 函数调用隐式地将调用参数的值赋值给函数的参数变量
- 返回语句会隐式地将返回操作的值赋值给结果变量
- 复合类型的字面量所产生的赋值行为
medals := []string{"gold", "silver", "bronze"},赋值行为:medals[0] = "gold"
类型
类型声明语句一般在包级,<类型名>首字母大写则包外可见。类型声明语句如下:
1 | type <类型名> <底层类型> // type Celsius float64 |
类型转换操作,每一类型T,都有对应的类型转换操作T(x),用于将x转为T类型。只有当两个类型的底层基础类型相同时,才允许这种转型操作。
命名类型可为该类型的值定义新行为,行为表现为一组关联到该类型的函数集合,称之为类型方法集
1 | type Celsius float64 // 创建命令类型 |
包和文件
Go语言中的包(package),目的是为了支持模块化、封装、单独编译和代码重用
一个包中保存在一个或多个以.go为文件后缀名的源文件,包级别的名字在同一个包的其他源文件可以直接访问,逻辑上所有代码都在一个文件一样
包所在目录路径是包的导入路径,e.g., 包导入路径: gopl.io/ch1/helloworld,目录路径: $GOPATH/src/gopl.io/ch1/helloworld
每个包对应一个独立的名字空间,通过首字母大小写控制包外可见性
导入包
每个包都有一个全局唯一的导入路径
每个包还有一个包名,包名命名以短小原则为主。一般而言,包名和包的导入路径的最后一个字段相同。e.g., gopl.io/ch2/tempconv,包名为tempconv
包被导入却没有使用会引发编译错误
包初始化
包的变量初始化:按变量声明顺序初始化,但变量间有依赖优先初始化被依赖变量
1 | var a = b + c // a 第三个初始化, 为 3 |
包内有多个.go源文件,按照发给编译器顺序初始化,Go语言构建工具首先按.go文件的文件名字典顺序排序,然后依次传给编译器
初始化工作可交由init()初始化函数完成,init()初始化函数有以下特点:
每个
.go文件可包含多个init()初始化函数init()初始化函数不能被调用,无传参- 多个
init()初始化函数,在程序执行时,按声明顺序被自动调用
包的初始化顺序如下图所示:
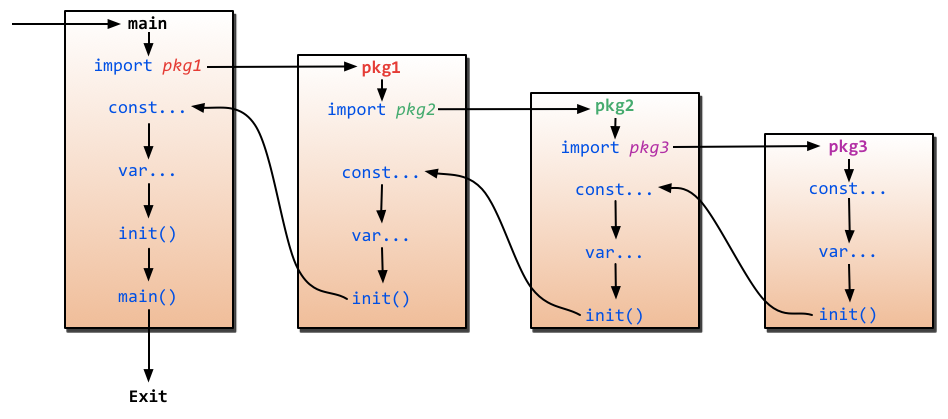
- 初始化依赖包:初始化一个包前,必须完全初始化其所依赖的包,按包出现顺序初始化并且每个包只会初始化一次(即使多次引用也一次)
- 初始化const常量:初始化完依赖包后,以下的都属于包内初始化。首先是
const常量的初始化 - 初始化var全局变量:按全局变量声明顺序初始化,但全局变量间有依赖优先初始化被依赖变量
- 初始化init()函数:按声明顺序初始化
init()函数,若包内有多个.go文件,按文件名字典顺序初始化.go文件 - main()函数
作用域
包级作用域:包内函数外定义,必须以
var方式声明(不能简短声明),包内多个文件皆可使用,包外可见性以首字母大小写决定。包级作用域的变量,声明顺序不影响作用域范围1
2
3
4var age int // 包级作用域
func main() {
...
}函数作用域:传入参数(非外部引用型)、返回值声明参数、函数内部声明参数,以上都只能在函数内部使用。若外部有同名变量则内部覆盖外部
1
2
3
4
5// str/name/age 都是函数作用域
func test(str string) (name string) {
age := 18
...
}1
2
3
4
5
6
7
8var cwd string
func init() {
cwd, err := os.Getwd() // 此处cwd为重新声明定义的变量,与包级cwd无丝毫关系,为init()函数作用域变量
if err != nil {
log.Fatalf("os.Getwd failed: %v", err)
}
}for/if/switch局部作用域
1
2
3
4
5if f, err := os.Open(fname); err != nil { // if局部作用域,只在if词法域中有效
return err
}
f.ReadByte() // f 为if局部作用域变量,if外无法使用,f未定义
f.Close() // compile error: undefined f
数据类型
Go语言中数据类型分为4类:
- 基础类型:numeric、string、bool
- 复合类型:array、struct
- 引用类型:point、slice、map、channal、function
- 接口类型:interface
基础类型
Integer
- 有符号整型:
int8、int16、int32(rune)、int64(-2^(N-1)~2^(N-1)-1) - 无符号整型:
uint8(byte)、uint16、uint32、uint64(0~2^N - 1) - 依赖系统类型:
int、uint(32位系统为int32、uint32,64位系统为int64、uint64)
二元运算优先级:上 > 下、左 > 右、可使用()提升优先级、%的符号和被取模数符号一致、/结果精度根据操作数定
1 | * / % << >> & &^ |
Float
- 单精度浮点型:
float32 - 双精度浮点型:
float64
Complex
complex64:对应float32complex128:对应float64
Bool
truefalse
String
字符串是数个8位字节(8-bit bytes)的集合,通常是UTF-8编码的文本(可为其他编码)
字符串是不可改变的字节序列 (意味若两个字符串共享相同的底层数据是安全的),由于字符串不可改变,所以每次更改字符串需要重新分配一块新内存空间
Go的字符串有2种形式:
解析性字符串:带
“”的字节序列1
2s := "hello world"
fmt.Println(s) // hello world原生字符串:带反引号的字符序列
1
2s := `hello world\n`
fmt.Println(s) // hello world\n // \n会被原样输出
len()函数返回字符串中的字节数;str[i]索引操作返回第i个字节值(0<= i <len(str)),超出索引范围会引发panic
str[i:j]子字符串操作返回第i个字节到第j-1个字节(并非第j个字节)
+操作拼接两个字符串
1 | s := "hello, world" // len(s) == 12 |
由于字符串不可改变,所以若想单独修改字符串中的字符,则需要将string转换为[]byte,修改完后再转换回string ([]byte既是[]uint8)
1 | s := "hello world" |
string转为rune,rune是int32别名(byte是uint8别名),代表字符的Unicode编码,使用4个字节存储,将string转成rune就意味着任何一个字符都用4个字节来存储其Unicode值
1 | s2 := "Go语言" |
string转为numeric需要使用到strconv包:
strconv.Itoa:inttostring1
2i := 123
s := strconf.Itoa(i) // s 为 string类型,值为"123"strconv.Atoi:stringtoint1
2s3 := "123"
i, err := strconv.Atoi(s3) // i 为 int类型,值为123
Const
常量的值在编译阶段确定而非运行时,常量的底层类型都是基础类型(bool/numeric/string),常量的值不可修改,常量的二元运算结果也是常量
批量声明常量,除第一个必须有初始化表达式外,其余的可省略,省略则默认使用前面的初始化表达式
1 | const pi float64 = 3.14 // const pi = 3.14 省略type也可,自动根据表达式确认type |
iota常量生成器,用于以相似规则生成常量。const声明语句中,第一个变量声明所在行iota将置0,然后每个有常量声明的行都+1,iota按行递增
若iota生成器被打断后,需要显示用iota恢复
1 | const ( |
复合类型
Array
数组是由特定元素组成的固定长度序列([length]type),通过索引下标访问元素(0 ~ len(array) - 1)
数组长度是数组类型的组成部分,数组长度在编译阶段确定,故[3]int和[4]int是两个不同的数组类型
若[length]type中length用...代替,表示数组长度根据初始化值的个数决定
相同类型的数组(length和type都相同)可进行比较,不同类型的数组进行比较会编译出错panic
1 | var array [3]int |
Slice
切片是由特定元素组成的可变长序列([]type),通过索引下标访问元素(0 ~ cap(slice))
slice和array不同,slice间不能进行比较,slice唯一能进行比较操作的是和nil,零值slice等于nil(nil值的slice无底层array),但判断slice是否为空不能用s == nil,使用len(s) == 0
slice由3部分组成:
- 指针
pointer:指向第一个slice元素对应的底层array元素的地址 (slice的第一个元素不一定就是array的第一个元素) - 长度
length:slice的元素个数 (length <= capacity),可使用len(slice)获得 - 容量
capacity:slice元素的最大个数,可使用cap(slice)获得
1 | // src/runtime/sort.go |
slice切片操作s[i:j](0<=i<=j<=cap(s)),获取第i个元素到第j-1个元素,len(s[i:j])为j-i,cap(s[i:j])为cap(s)-i
1 | func main() { |
可使用内置的make()函数创建slice,make()创建一个匿名的数组变量并初始化赋值对应类型的零值,然后返回一个slice
1 | // make([]T, len) |
使用append()函数向slice追加元素,使用append()函数必须注意一点:调用append()函数是,会先检测slice是否有足够的capacity保存新元素,如果有足够容量则直接扩展slice,保持底层数组不变;如果没有足够容量会先分配一个capacity * 2的新slice,然后将原slice内容复制到新slice,最后再添加新元素,由于新分配了内存空间,所以底层数组改变。
1 | s := []int{1, 2, 3} |
1 | a := make([]int, 0, 10) // a ---> 0x1234 无(data) 0(length) 10(capacity) |
1 | s := []int{5} // 0x1234(array add) 5(data) 1(length) 1(capacity) |
slice小技巧
1 | // 合并两个slice |
Map
map是无序的key/value对集合,map[K]V。map中所有key为同一类似,所有value为同一类型
map的key类型必须为支持比较操作==的数据类型,所以slice、map 和 function类型无法做为map的key。map的key类型无任何限制
1 | func echo() string { |
创建map可直接使用内置make()函数,也可用map字面值初始化方式
1 | ages := make(map[string]int) // make()方式创建 |
map通过key下标访问value;通过delete()删除元素;通过for/range遍历map,遍历输出的顺序是随机的;通过if/ok判断是否存在value
1 | fmt.Println(ages['alice']) // 31 |
声明map后必须要创建map后才可进行赋值操作
1 | var testMap map[string]int |
map中的value是不可寻址的,对map的value进行取地址操作或让value出现在赋值语句=左边都会引起panic
1 | _ := &ages["alice"] // panic!!! cannot take the address of ages["alice"] map中value不可寻址 |
1 | type Student struct { |
Struct
struct结构体是由零个或多个任意类型的值组合而成,值称为结构体的成员,成员通过.点操作符访问,如:struct.member,不包含任何成员的结构体为空结构体struct{}
1 | type Employee struct { // 声明struct |
相同类型的结构体是可以进行比较的,结构体是否是相同类型,取决于以下2点:
- 成员类型、成员个数相同
- 成员顺序相同
成员名首字母是否大小写决定其能否导出,首字母大写的成员可导出(包外可访问)
复合类型(array、struct)的值不能包含其自身,即S结构体类型将不能再有S类型的成员,但可有*S指针类型的成员
struct允许嵌套,即一个struct中嵌入另一个struct
1 | type Point struct { |
struct还支持匿名成员,即只声明成员的类型,而不指名成员的名称,但匿名成员的类型必须是命名类型或指向命名类型的指针。其实匿名成员的名称既是其命名类型的名称(隐式名称),由于此,所以不能有两个类型相同的匿名成员,否则会导致成员名称冲突
1 | type Point struct { |
Json
在需要对struct结构体成员添加额外元信息时,会使用到成员tag。通常以key:“value”形式存在,key为encoding/<key>包的名称,表示添加哪种格式的信息
1 | type Movie struct { |
struct to json
1 | jsonBytes, err := json.Marshal(movies) |
json to struct
1 | jsonStr := `{ |
map to json
1 | mapJson := map[string]interface{}{ |
json to map
1 | jsonStr := `{ |